
Pretrained model machine vision systems serve as the backbone of modern technology, enabling machines to process and understand visual data effectively. These systems come pre-equipped with knowledge gained from analyzing vast datasets, which allows them to recognize patterns, objects, and features in images or videos. For example, using a pretrained model machine vision system, tasks like object classification can take minutes instead of hours. This efficiency is evident in studies where the fastest pretrained model processed over 69,000 cases in just 6 minutes, compared to the 384 hours it would take manually.
By leveraging pretrained model machine vision systems, you can bypass the need for extensive training from scratch. This approach not only saves time but also enhances accuracy, as these models benefit from large-scale datasets and advanced architectures. Their role in computer vision simplifies AI development, making it accessible to researchers and developers of all skill levels.
Key Takeaways
-
Pretrained models save time by skipping long training processes. You can adjust them for specific tasks, cutting development time a lot.
-
Pretrained models improve accuracy. They study big datasets to find patterns and do well in tasks like sorting images.
-
Pretrained models are cheaper. They use fewer expensive computer tools and lower costs for building and running systems.
-
These models are easier for developers to use. You don’t need to be an AI expert because many free tools and simple platforms exist.
-
It’s important to think about ethics when using pretrained models. Check the training data for unfairness and use them responsibly to avoid problems.
Importance of Pretrained Models in Machine Vision

Efficiency in Development and Deployment
Pretrained models significantly enhance the efficiency of developing and deploying machine vision systems. By using a pretrained model, you can skip the time-consuming process of training a model from scratch. Instead, you start with a model that already understands basic visual patterns, such as edges, textures, and shapes. This allows you to focus on fine-tuning the model for your specific task, saving both time and computational resources.
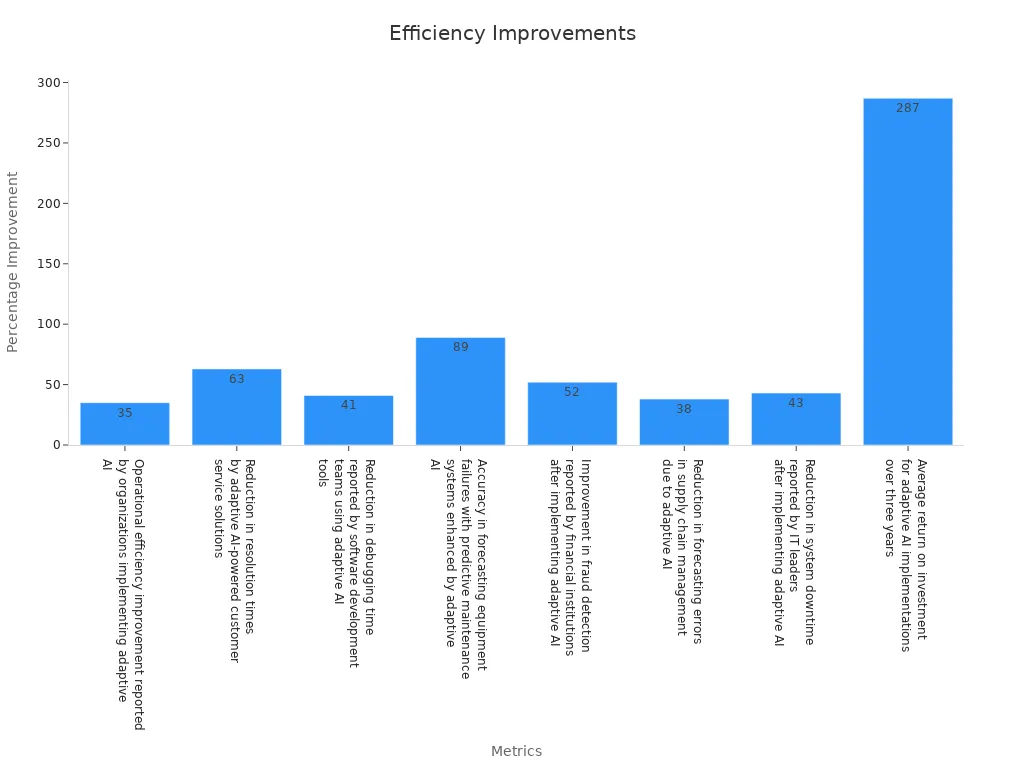
Organizations adopting pretrained AI models have reported remarkable improvements in operational efficiency. For instance, a Gartner study in 2023 revealed a 35% boost in efficiency for companies implementing adaptive AI. Similarly, customer service solutions powered by pretrained models reduced resolution times by 63%, while software development teams experienced a 41% decrease in debugging time. These statistics highlight how pretrained models streamline workflows across various industries.
Improved Accuracy with Large-Scale Pretraining
Pretrained models excel in accuracy, thanks to their exposure to vast datasets during the pretraining phase. This large-scale pretraining enables the model to learn intricate patterns and relationships within the data, which translates to better performance on downstream tasks. For example, a study benchmarking pretrained deep learning models on the Microsoft ASIRRA dataset demonstrated that the NASNet Large model achieved an impressive 99.65% accuracy in image classification tasks. This was accomplished with minimal adjustments to the model’s hyperparameters, showcasing the power of pretrained models in delivering high accuracy with minimal effort.
Research also shows that the performance of pretrained models scales with both model capacity and data quantity. A 7-billion-parameter model pretrained on 2 billion images achieved 84.0% accuracy on ImageNet-1k, with no signs of performance saturation. This indicates that as you increase the size of the model and the dataset, the accuracy continues to improve, making pretrained models a reliable choice for complex machine vision tasks.
Cost-Effectiveness and Resource Optimization
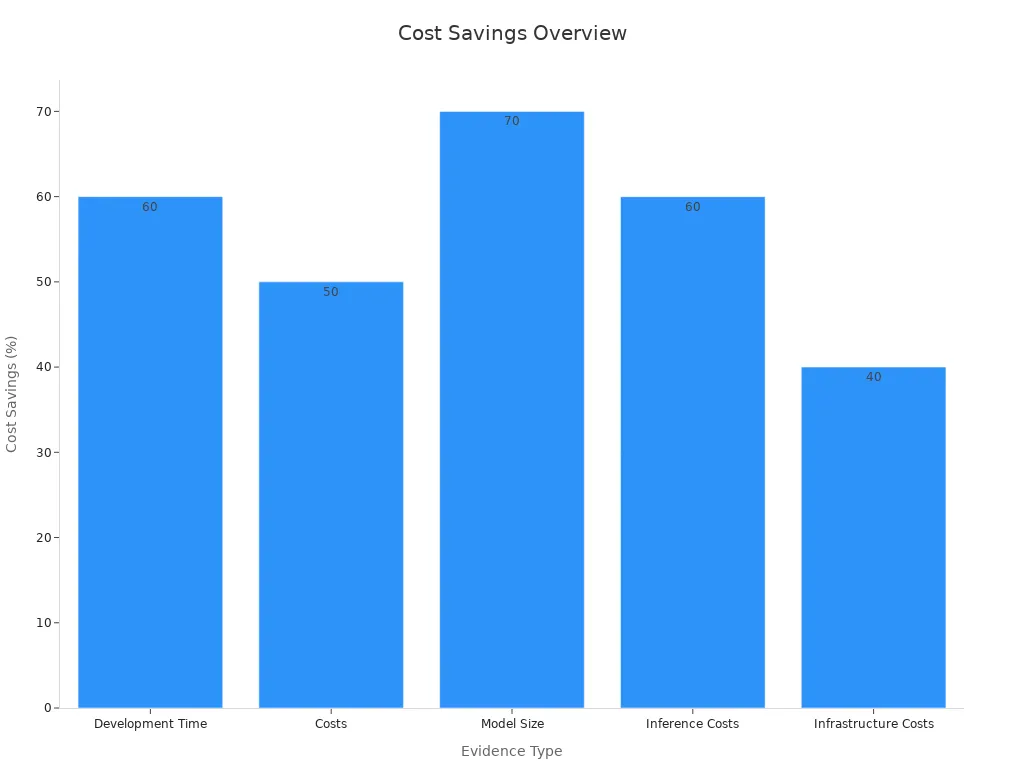
Pretrained models offer a cost-effective solution for building machine vision systems. Training a model from scratch requires significant computational resources, time, and expertise. By leveraging pretrained models, you can reduce these costs substantially. For example, fine-tuning a pretrained GPT-4 model can cut development time by 60%. Additionally, using techniques like model distillation can reduce model size by 70%, leading to a 60% decrease in inference costs.
Organizations also benefit from serverless architectures that optimize resource usage based on actual demand. This approach reduces infrastructure costs by 40%, making pretrained models an economically viable option for businesses of all sizes. By adopting pretrained models, you not only save money but also minimize the environmental impact of AI development by reducing energy consumption.
Accessibility for developers and researchers
Pretrained models have revolutionized accessibility for developers and researchers, making advanced machine vision systems easier to use and adapt. You no longer need to start from scratch or possess deep expertise in AI to leverage these models effectively. Instead, you can access tools and resources that simplify the process of building and fine-tuning machine vision systems.
Open-source pretrained models play a key role in this transformation. These models provide transparency in their architecture, allowing you to understand how they work and replicate their functionality. For example, standardized training datasets are often shared alongside these models, enabling you to reproduce results and experiment with the same data. This openness fosters collaboration and innovation within the AI community.
Here are some ways pretrained models enhance accessibility:
-
Open-source models let you create and test code that meets accessibility standards, ensuring your applications are inclusive.
-
Transparent architectures help you modify and fine-tune models, making it easier to adapt them to your specific needs.
-
Standardized datasets allow you to replicate experiments and validate findings, promoting reproducibility in research.
-
Integration with authoring tools encourages you to improve accessibility practices in your projects.
By using pretrained models, you gain access to a wealth of resources that streamline development and research. These models reduce barriers to entry, enabling you to focus on solving real-world problems rather than grappling with complex AI training processes. Whether you’re a seasoned researcher or a beginner, pretrained models empower you to explore machine vision with confidence and creativity.
How Pretrained Models Work in Machine Vision Systems
Overview of the Training Process
Pretrained models undergo a rigorous training process to achieve their high performance. This process begins with selecting a suitable model architecture, such as EfficientNetB0, which is commonly used for its efficiency and accuracy. The model is initially trained on a large dataset like ImageNet, which contains millions of labeled images. During this phase, the model learns to identify basic visual patterns, such as edges, textures, and shapes.
To enhance the model’s performance, techniques like transfer learning are applied. Transfer learning involves reusing the knowledge gained from one task to improve performance on a related task. For example, a pretrained model trained on ImageNet can be adapted to classify medical images with minimal additional training. Image augmentation techniques, such as flipping, rotating, or cropping images, are also employed to artificially expand the dataset size. This helps the model generalize better to unseen data.
Key metrics, such as accuracy, precision, and recall, are used to evaluate the model’s performance during training. For instance, a deep learning model trained with transfer learning achieved an accuracy of 0.96, precision of 0.95, and recall of 0.97. These metrics highlight the effectiveness of the training process in creating robust pretrained models.
Role of Large Datasets in Pretraining
Large datasets play a crucial role in the success of pretrained models. These datasets often contain billions of rows, providing the model with diverse examples to learn from. By exposing the model to a wide variety of images, it can recognize patterns and make accurate predictions across different tasks. For instance, a pretrained AI model trained on a dataset with billions of images can excel in tasks like object detection and image segmentation.
The quality of the dataset is just as important as its size. Poor-quality data can lead to subpar model performance, even if the dataset is large. High-quality datasets ensure that the model learns meaningful patterns rather than noise. This is why researchers invest significant effort in curating and cleaning datasets before using them for pretraining.
|
Evidence Summary |
Importance |
|---|---|
|
Large datasets, often with billions of rows, are essential for building effective models. |
They are crucial for training models to recognize patterns and make accurate predictions. |
|
Compromising on data quality can lead to poor model performance. |
Reinforces the necessity of large datasets for achieving high-quality pretrained models. |
Fine-Tuning Pretrained Models for Specific Tasks
Fine-tuning allows you to adapt a pretrained model to a specific task, making it more relevant and effective. This process involves training the model on a smaller, task-specific dataset while retaining the knowledge it gained during pretraining. For example, you can fine-tune a pretrained model designed for general object detection to identify specific objects, such as medical anomalies or industrial defects.
Fine-tuning offers several advantages. It significantly reduces training time compared to training a model from scratch. Studies show that fine-tuning can cut training time by up to 90%. It also improves performance on specific tasks by 10-20% or more. Metrics like accuracy, precision, and recall are commonly used to measure the effectiveness of fine-tuning. For instance, a fine-tuned model can achieve high precision and recall, ensuring that it identifies true positives while minimizing false positives.
|
Metric |
Description |
|---|---|
|
Accuracy |
Measures the percentage of correct predictions made by the model. |
|
Precision |
Percentage of true positive predictions among all positive predictions. |
|
Recall |
Percentage of true positive predictions among all actual positive samples. |
|
F1-score |
Harmonic mean of precision and recall. |
|
Intersection over Union (IoU) |
Measures the overlap between predicted and actual bounding boxes or masks. |
|
Mean Average Precision (mAP) |
Average precision across multiple thresholds for the IoU metric. |
|
Mean Intersection over Union (mIoU) |
Average IoU across multiple classes, commonly used for semantic segmentation problems. |
Fine-tuning also enables the model to adapt to domain-specific data, enhancing its relevance. For example, a pretrained model trained on general images can be fine-tuned to work with satellite imagery, making it suitable for applications like land-use classification or disaster monitoring.
Transfer learning and its impact on machine vision
Transfer learning has revolutionized the way you can build and improve machine vision systems. Instead of training a model from scratch, you can take a pretrained model and adapt it to solve a new problem. This approach saves time, reduces the need for massive datasets, and improves performance on specialized tasks.
What is Transfer Learning?
Transfer learning is like teaching someone a new skill by building on what they already know. Imagine you’ve learned how to ride a bicycle. When you try to learn how to ride a motorcycle, you don’t start from zero. You already understand balance and steering, so you only need to focus on the new controls. Similarly, in transfer learning, a model trained on one task (like recognizing animals) can be fine-tuned to perform a related task (like identifying specific dog breeds).
Why is Transfer Learning Important in Machine Vision?
Machine vision tasks often require analyzing complex visual data. Training a model from scratch for these tasks can take weeks or even months. Transfer learning simplifies this process by reusing knowledge from existing models. Here’s how it impacts machine vision:
-
Speeds Up Development: You can skip the initial training phase and focus on fine-tuning the model for your specific needs. This reduces development time by up to 90%.
-
Reduces Data Requirements: Instead of needing millions of labeled images, you can train the model with a smaller dataset. For example, a pretrained model trained on ImageNet can be fine-tuned with just a few thousand images for tasks like medical imaging.
-
Improves Accuracy: Pretrained models already understand basic visual patterns. This foundation helps them achieve higher accuracy when adapted to new tasks.
Tip: If you’re working on a niche application, transfer learning can help you achieve great results without requiring a massive dataset or expensive hardware.
How Does Transfer Learning Work?
Transfer learning typically involves three steps:
-
Choose a Pretrained Model: Select a model that has been trained on a large dataset, such as ResNet or VGG, which are popular for image recognition tasks.
-
Freeze the Base Layers: Keep the initial layers of the model unchanged. These layers contain general features like edges and textures that are useful for most tasks.
-
Fine-Tune the Top Layers: Replace the final layers with new ones tailored to your specific task. Train these layers on your dataset to adapt the model to your needs.
Here’s a simple example in Python using TensorFlow:
from tensorflow.keras.applications import ResNet50
from tensorflow.keras.models import Model
from tensorflow.keras.layers import Dense, Flatten
# Load a pretrained ResNet50 model
base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3))
# Freeze the base layers
for layer in base_model.layers:
layer.trainable = False
# Add custom layers for fine-tuning
x = Flatten()(base_model.output)
x = Dense(128, activation='relu')(x)
output = Dense(10, activation='softmax')(x)
# Create the new model
model = Model(inputs=base_model.input, outputs=output)
This code demonstrates how you can reuse a pretrained ResNet50 model and adapt it for a new classification task.
Real-World Impact of Transfer Learning in Machine Vision
Transfer learning has enabled breakthroughs in various industries. Here are some examples:
-
Healthcare: Pretrained models fine-tuned on medical datasets can detect diseases like cancer with high accuracy. For instance, a model trained on chest X-rays can identify pneumonia with minimal additional training.
-
Autonomous Vehicles: Transfer learning helps self-driving cars recognize road signs and obstacles by adapting general-purpose models to specific driving environments.
-
Retail: Retailers use transfer learning to build models that analyze customer behavior through video feeds, improving store layouts and product placements.
|
Industry |
Application |
Impact |
|---|---|---|
|
Healthcare |
Disease detection in medical imaging |
Faster diagnosis and improved patient outcomes |
|
Automotive |
Object detection for self-driving cars |
Safer navigation and reduced accidents |
|
Retail |
Customer behavior analysis |
Enhanced shopping experiences |
Key Takeaways
Transfer learning empowers you to build powerful machine vision systems without starting from scratch. It saves time, reduces costs, and improves accuracy, making it an essential tool for developers and researchers. Whether you’re working on healthcare, automotive, or retail applications, transfer learning can help you achieve your goals faster and more efficiently.
Note: Always evaluate the ethical implications of using pretrained models, especially when working with sensitive data like medical records or facial recognition.
By leveraging transfer learning, you can unlock the full potential of machine vision systems and bring your projects to life with less effort and greater impact.
Applications of Pretrained Models in Machine Vision

Object Detection and Classification
Pretrained models play a vital role in object detection and classification tasks. These tasks involve identifying objects in an image and determining their categories. For example, a pretrained model machine vision system can detect cars, pedestrians, and traffic signs in real-time. This capability is essential for applications like surveillance, retail analytics, and autonomous systems.
Pretrained models excel in these tasks by leveraging transfer learning. They use knowledge gained from large datasets to enhance performance, even when working with smaller or specialized datasets. Modern models like YOLO (You Only Look Once) and Faster R-CNN are optimized for speed and accuracy, making them suitable for real-time applications. These models also handle challenges like detecting small or overlapping objects and adapting to varied lighting conditions.
|
Challenge |
Solution |
|---|---|
|
Classifying objects and pinpointing locations |
Regional-based CNNs like Fast R-CNN |
|
Real-time detection requirements |
Optimized frameworks like YOLO |
|
Handling objects of various sizes and shapes |
Feature Pyramid Network (FPN), Anchor Boxes |
|
Limited annotated data |
Transfer Learning, Data Augmentation |
|
Class imbalance |
Focal Loss, Hard Negative Mining |
Pretrained models simplify these complex tasks, enabling you to achieve high accuracy and efficiency in object detection and classification.
Facial Recognition and Biometric Systems
Facial recognition and biometric systems rely heavily on pretrained models to deliver accurate and reliable results. These systems identify individuals by analyzing facial features, fingerprints, or other biometric data. Pretrained AI models trained on diverse datasets can adapt to different resolutions and lighting conditions, ensuring robust performance.
For instance, pretrained models like VGG16-PSN and APS achieve impressive accuracy rates in facial recognition tasks. The table below highlights their performance:
|
Model |
Accuracy Rate (%) |
|---|---|
|
VGG16-SSN |
86.79 |
|
VGG16-PSN |
87.13 |
|
APS |
91.55 |
|
Proposed Method |
97.11 |
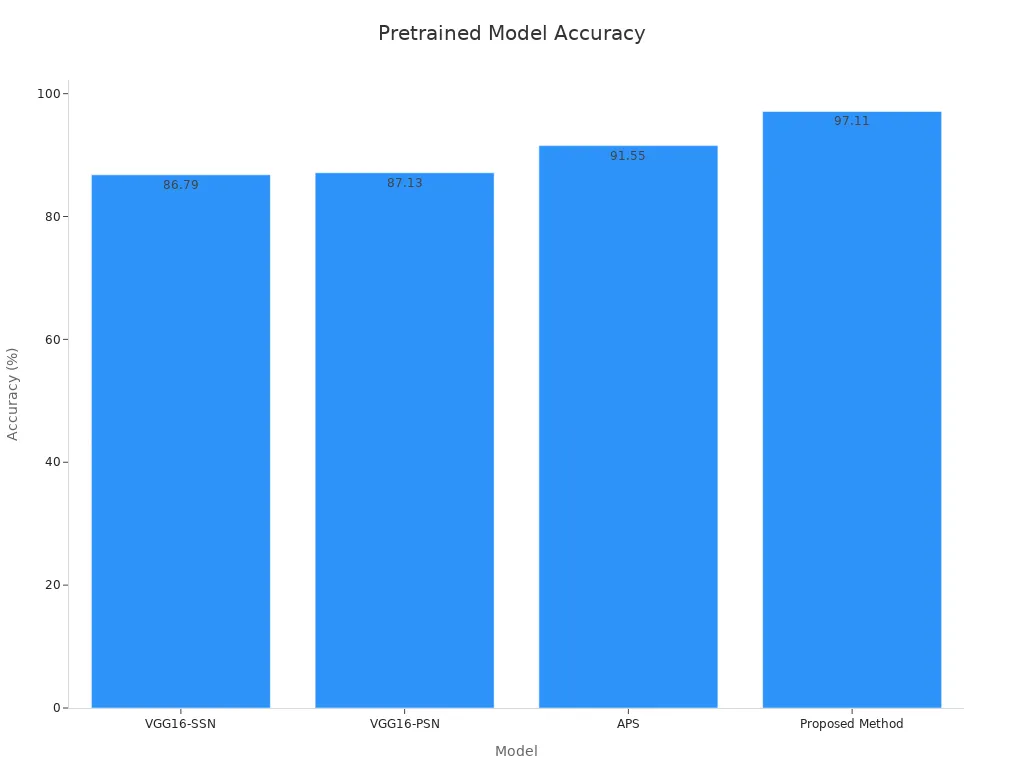
These models also perform well across various resolutions, from 15×15 to 100×100 pixels. However, recognizing faces at lower resolutions remains challenging due to limited image details. By using pretrained models, you can build systems that excel in security, authentication, and access control applications.
Autonomous Vehicles and Navigation
Autonomous vehicles and navigation systems depend on pretrained models to interpret their surroundings. These models process data from cameras, LiDAR, and other sensors to identify objects, predict movements, and make driving decisions. Pretrained models like ViDAR++ and UniPAD enhance the robustness of these systems by fusing multi-modal sensor data and bridging 2D and 3D representations.
|
Model |
Description |
|---|---|
|
ViDAR++ |
Fuses multi-modal sensor data (LiDAR, cameras) with high-level semantic cues for enhanced robustness. |
|
UniPAD |
Bridges 2D and 3D representations, achieving superior performance across diverse sensor modalities. |
|
UniWorld |
Leverages pre-trained world models to anticipate future states, improving adaptability in dynamic settings. |
|
BEVWorld |
Integrates multi-modal inputs into a cohesive latent space, demonstrating robust generalization. |
|
DriveWorld |
Employs a 4D scene understanding framework, bridging simulated and real-world environments effectively. |
These pretrained models enable vehicles to navigate safely in dynamic environments, even under challenging conditions. By integrating pretrained models into navigation systems, you can improve adaptability, reduce accidents, and enhance overall driving efficiency.
Industrial automation and quality control
Pretrained models have transformed industrial automation and quality control by enabling machines to inspect products with precision and efficiency. These models analyze visual data to detect defects, classify items, and ensure production standards are met. For example, a pretrained convolutional neural network (CNN) can identify manufacturing flaws in real-time, reducing human error and improving overall productivity.
To implement pretrained models effectively, you need to follow key steps:
-
Algorithm Selection: Choose models suited for quality control tasks, such as CNNs for image inspection.
-
Training and Validation: Train the model on labeled datasets and validate its accuracy using test data.
-
Hyperparameter Tuning: Adjust parameters to minimize misclassification rates and enhance performance.
Quality control metrics validate the feasibility of pretrained models in industrial settings. These metrics ensure the system performs reliably and meets production standards. The table below highlights key metrics:
|
Metric |
Value Range |
Description |
|---|---|---|
|
False Positive Rate |
0.03% to 0.30% |
Indicates the percentage of non-defective products incorrectly rejected. |
|
False Negative Rate |
0% to 0.07% |
Indicates the percentage of defective products incorrectly accepted. |
|
Rejection Rate |
0.64% to 5.09% |
Percentage of total production rejected based on quality control criteria. |
|
Detection Rate |
At least 99.93% |
Percentage of sealing defects successfully detected during inspection. |
Pretrained models also simplify dataset preparation and fine-tuning, allowing you to adapt them to specific manufacturing environments. By leveraging these models, you can achieve higher detection rates, reduce waste, and optimize production processes.
Tip: Proper assessment of algorithms and datasets is crucial for successful implementation. Fine-tuning pretrained models can significantly improve accuracy in detecting defects.
Medical imaging and diagnostics
Pretrained models have revolutionized medical imaging and diagnostics by enabling faster and more accurate disease detection. These models analyze complex medical data, such as MRI scans or CT images, to identify abnormalities that might be missed by human eyes. For instance, a pretrained model can detect brain tumors or kidney stones with remarkable precision, improving patient outcomes.
Diagnostic accuracy rates demonstrate the effectiveness of pretrained models in healthcare. The table below showcases their performance across various modalities:
|
Modality |
Accuracy Rate |
|---|---|
|
Binary Classification |
98.08% |
|
Multi-Class Classification |
87.02% |
|
MRI |
92% |
|
CT |
100% |
|
CXR |
83% |
|
CXR Datasets |
84% – 99% |
|
CT Datasets |
90% – 99% |
|
Brain MRI |
96% |
|
Kidney CT |
100% |
|
CXR |
95% |
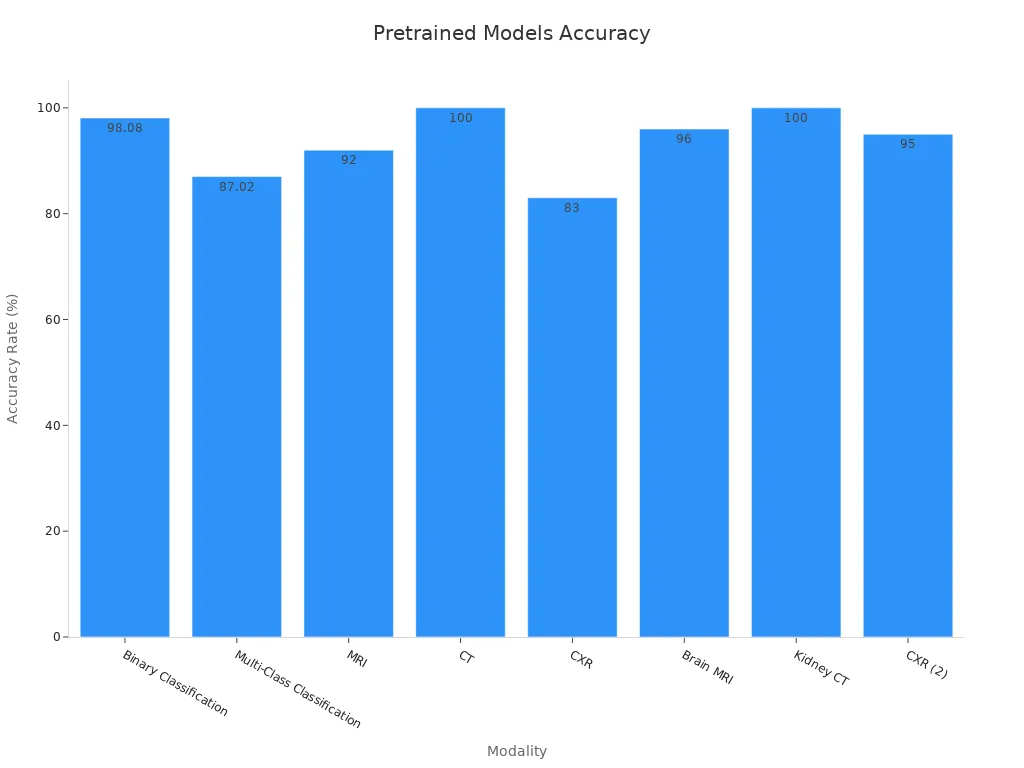
Pretrained models excel in tasks like binary classification, multi-class classification, and segmentation. Ensemble methods further enhance accuracy, especially when applied to datasets like chest X-rays (CXR) and computed tomography (CT) scans. For example, VGG16 achieves 96% accuracy for brain MRI and 100% for kidney CT, showcasing its reliability in critical applications.
By using pretrained models, you can streamline diagnostic workflows, reduce the time required for analysis, and improve the consistency of results. These advancements empower healthcare professionals to focus on patient care while relying on AI for accurate and efficient diagnostics.
Note: Always ensure ethical considerations when using pretrained models in medical applications, especially when handling sensitive patient data.
Where to Find Pretrained Models for Machine Vision Systems
Popular platforms like TensorFlow Hub and PyTorch Hub
You can find pretrained models on platforms like TensorFlow Hub and PyTorch Hub. These platforms provide a wide range of models for tasks such as image classification, object detection, and text generation. TensorFlow Hub offers models like Inception for recognizing objects in images and MobileNet for lightweight applications. PyTorch Hub features models like ResNet, known for its accuracy in image classification, and Faster R-CNN, which excels in object detection.
|
Platform |
Task |
Model Name |
Features/Performance Metrics |
|---|---|---|---|
|
TensorFlow Hub |
Image Classification |
Inception |
Good performance in recognizing objects within images. |
|
TensorFlow Hub |
Image Classification |
MobileNet |
Efficient and lightweight, designed for mobile applications. |
|
TensorFlow Hub |
Object Detection |
SSD |
Real-time object detection with bounding boxes and class labels. |
|
PyTorch Hub |
Image Classification |
ResNet |
Known for depth and accuracy in image classification tasks. |
|
PyTorch Hub |
Object Detection |
Faster R-CNN |
Provides bounding box coordinates and class labels for objects. |
These platforms simplify access to pretrained models, allowing you to integrate them into your projects quickly.
Open-source repositories and model zoos
Open-source repositories and model zoos are excellent resources for pretrained models. Hugging Face Model Hub is a popular choice, offering models for tasks like text classification and sentiment analysis. Kaggle Models provides pretrained models from competitions, helping you build solutions faster. TensorFlow Hub also supports transfer learning and allows users to share their models.
-
Hugging Face Models Hub: Ideal for discovering pretrained models for various tasks.
-
Kaggle Models: A platform for sharing and finding pretrained models from competitions.
-
TensorFlow Hub: A repository for machine learning models, supporting transfer learning.
These repositories promote collaboration and innovation, making pretrained models accessible to everyone.
Pretrained models from companies like Google, NVIDIA, and OpenAI
Leading companies like Google, NVIDIA, and OpenAI offer advanced pretrained models. Google’s LaMDA has improved conversational AI by enhancing personalization and context-awareness. NVIDIA’s Llama-3.1-Nemotron-70B-Instruct ranks highly in alignment benchmarks, showcasing its ability to align with human preferences. OpenAI’s GPT models excel in generating human-like text and answering questions.
For example, NVIDIA’s Llama-3.1-Nemotron-70B-Instruct demonstrates its potential in educational applications like question answering and information retrieval. These advancements highlight the capabilities of pretrained AI models in solving complex problems across industries.
Tip: Explore these models to leverage cutting-edge technology for your machine vision projects.
Ethical considerations when using pretrained models
When using pretrained models, you must consider ethical implications to ensure responsible AI development. These models often inherit biases and risks from the datasets they are trained on, which can lead to unintended consequences.
One major concern involves the quality of the data used during pretraining. Datasets may include inappropriate content, such as biased, offensive, or violent material. For example, the model card for DeepFloyd/IF-II-M-v1.0 highlights that its training data contained adult and violent content. This raises questions about the suitability of such models for sensitive applications.
Bias and fairness also play a critical role in ethical AI usage. Pretrained models can unintentionally reinforce societal biases, leading to unfair outcomes. Techniques like pre-processing, in-processing, and post-processing can help mitigate these issues. By applying these methods, you can reduce bias and improve the fairness of your machine vision systems.
Another ethical challenge involves the potential misuse of pretrained models. These models can generate harmful content, spread disinformation, or violate privacy. For instance, malicious actors might use them to create deepfakes or unauthorized surveillance systems. To prevent misuse, you should implement safeguards and follow ethical guidelines when deploying these models.
|
Aspect |
Description |
|---|---|
|
Data Quality Concerns |
Issues related to inappropriate content in datasets, including biased, offensive, and violent content. For instance, the model card of DeepFloyd/IF-II-M-v1.0 notes that it was trained on a dataset containing adult and violent content. |
|
Bias and Fairness |
Discusses the importance of addressing bias in software development, with references to various techniques for mitigating bias in machine learning models, including pre-processing, in-processing, and post-processing methods. |
|
Malicious Use and Misuse |
Highlights the risks of deliberate misuse of models, including generating harmful content, disinformation, and violations of privacy, emphasizing the need for ethical considerations in AI model usage. |
Tip: Always review the dataset and model documentation before using pretrained models. This helps you identify potential risks and ensures your application aligns with ethical standards.
By addressing these ethical considerations, you can build machine vision systems that are not only effective but also responsible and fair.
Pretrained models have transformed machine vision systems, making them faster, more accurate, and accessible. These models, like AlexNet and Inception, have set benchmarks in computer vision. AlexNet established deep learning as the standard, while Inception improved efficiency and accuracy in handling complex visual data. For example, pretrained models achieved 93.63% accuracy on ScanObjectNN and 91.31% on ModelNet40, showcasing their reliability across industries.
From healthcare to autonomous vehicles, pretrained models drive innovation. They reduce development time, optimize resources, and improve outcomes. By exploring pretrained model machine vision systems, you can unlock new possibilities for your projects and contribute to advancing AI.
FAQ
What are pretrained models in machine vision?
Pretrained models are AI systems trained on large datasets to recognize patterns in visual data. They serve as a foundation for solving tasks like object detection or image classification. You can fine-tune these models for specific applications, saving time and resources.
How do pretrained models save time in AI development?
Pretrained models eliminate the need to train from scratch. They already understand basic visual features like edges and shapes. You only need to fine-tune them for your task, reducing training time by up to 90%.
Can you use pretrained models without coding experience?
Yes, many platforms like TensorFlow Hub and PyTorch Hub offer user-friendly interfaces. These platforms provide pretrained models that you can integrate into projects with minimal coding. Tutorials and documentation simplify the process further.
Are pretrained models suitable for small datasets?
Absolutely! Pretrained models excel with small datasets through transfer learning. They use prior knowledge from large datasets to adapt quickly to new tasks. This approach improves accuracy and reduces the need for extensive data collection.
What are the ethical concerns with pretrained models?
Pretrained models may inherit biases from their training data. This can lead to unfair outcomes or misuse, such as generating harmful content. Always review model documentation and apply fairness techniques to ensure ethical use.
Tip: Regularly audit your AI systems to identify and mitigate potential biases.
See Also
An Overview of Computer Vision and Machine Vision Technologies
The Role of Deep Learning in Advancing Machine Vision
The Use of Synthetic Data in Machine Vision Applications
Comparing Firmware Machine Vision to Conventional Systems
Grasping Object Detection Techniques in Today’s Machine Vision









